AZ-GTi を経緯台モードで INDI から操作する
AZ-GTi は廉価でコンパクトな自動導入経緯台です。ファームウェアをアップデートすることで赤道儀モードで動作させることもできます。
一方で、極軸合わせの手間を省いて手軽に扱いたい場合など、経緯台モードを使う場面は多いと思います。
INDI 経由で経緯台モードの AZ-GTi を操作をする場合に躓くところが多かったので共有します。
ドライバ
経緯台モードで使用する場合のドライバは Skywatcher Alt-Az です。
紛らわしいですが AZ-GTi ドライバは EQMod ドライバをベースにしたもので、赤道儀モード専用です。
接続方法1. USBケーブルを使う
下記の USB ケーブルを利用すると、Skywatcher Alt-Az ドライバで操作できます。
接続方法2. WiFi を使う
少し手間がかかりますが、AZ-GTi の WiFi を使えばケーブルレスで接続できます。
以下では INDI Server を Raspberry Pi 上で動かすものとします。
1. AZ-GTi と INDI Server を同一ネットワークに置く
いくつか接続パターンがあります。ホットスポットモードで AZ-GTi に RPi を繋ぐ、ステーションモードで WiFi ルーターに AZ-GTi と RPi を繋ぐ、など。
下記 URL にいくつかの方法が図示されています。
2. INDI のバージョンを 1.8.6 以上にする
1.8.5 以下では Skywatcher Alt-Az ドライバがネットワーク経由の操作に対応していません。
2020/07/10 現在、RPi の場合はソースからビルドすることで最新バージョンを利用することができます。
https://github.com/indilib/indi#building
https://github.com/indilib/indi-3rdparty#building
3. ドライバ設定

Connection Mode: Ethernet Address: 192.168.x.x (AZ-GTi の IP アドレスを指定) Port: 11880 Connection Type: UDP
以上で WiFi 経由での操作が可能になります。
参考
コンテナ時代の Twelve-Factor App
Twelve-Factor App (Adam Wiggins, 2012) を読んで感動したので、あらためてコンテナ技術が流行する 2016 年現在の Web アプリケーション環境を意識しながら覚え書き、まとめです。
本記事は主に Web アプリケーション開発者、Web アプリケーションインフラ構築に関わる方を対象としています。
Twelve-Factor App
Heroku が提唱するソフトウェア開発および CI 環境構築における方法論で、下記を大目的とした 12 の指針からなる。
- プロジェクトに新しく加わった開発者が要する時間とコストを最小化する
- 実行環境間での移植性を最大化する
- サーバー管理やシステム管理を不要なものにする
- 開発環境と本番環境の差異を最小限にし、アジリティを最大化する継続的デプロイを可能にする
- ツール、アーキテクチャ、開発プラクティスを大幅に変更することなくスケールアップできる
今回は特に Docker による Web アプリケーション開発および CI 環境構築を意識して、以下の 8 つの指針を抜粋し、要約と共に Docker への適用例 を考察する。
- 継続的デプロイのためのアプリケーション構成
- I . コードベース
- III. 設定
- V . ビルド、リリース、実行
- アプリケーションプロセスの管理とスケール
- VI. プロセス
- VIII. 並行性
- IX. 廃棄容易性
- 運用
- XI. ログ
- XII. 管理プロセス
継続的デプロイのためのアプリケーション構成
アジリティの高い、身軽なアプリケーション構成 のための方針、および共通概念。
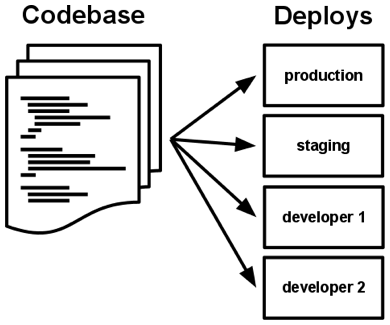
I. コードベース
- バージョン管理された コードベース と、一対一対応するアプリケーション
- 一つのコードベース・アプリケーションは、複数の デプロイ (ステージング環境、本番環境、開発環境) を生ずる
III. 設定
アンチパターンとして、コードへの定数べた書き、Rails の database.yml への値のべた書きが挙げられている。良しとされない理由としては、
- 誤ってリポジトリにチェックインされやすい
- いろんな場所、いろんなフォーマットに散乱しがち
ことが挙げられている。
V. ビルド、リリース、実行
ビルド、リリース、実行の 3 つのステージを厳密に分離する。
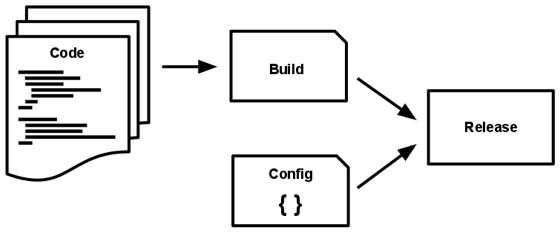
- ビルドステージ
- 特定バージョンのコードリポジトリから ビルド (実行可能な塊) への変換
- リリースステージ
- ビルドに対してデプロイの設定 (環境毎に異なる値、前節参照) を結合し、リリース を作成する
- 実行ステージ
- リリースに対して、必要なプロセスを起動することでアプリケーションを 実行 する
ビルドステージでは、バイナリやアセットファイルのコンパイル、依存ライブラリの取得などが行われる。リリースステージによって環境依存の設定が埋め込まれ、いつでも実行できる状態となる。
ビルドには環境に依存する値 (RAILS_ENV や DB ホスト / パスワード) は含まれない。 このことは逆に、コードベースからデプロイに至るプロセスを、設定を介して "環境に依存しないビルド" と "環境の依存があるリリース" の二段階の概念に分けた、とも考えられる。
🐳 Docker への適用
- 1 つのコードベースから 1 つのアプリケーションを成す Docker イメージ群を生成する
- nginx イメージ & rails イメージなど
- ビルドステージでは、コンパイルや依存ライブラリの取得と同時に、Dockerfile のビルドを行う
- Docker イメージ群は環境依存の値を含まない
- リリースステージで設定 (環境変数) を埋め込むことで、実行可能になる
- Docker Compose の docker-compose.yml や、ECS の Task Definition によって実現する
- 実行ステージでは Docker Compose や、コンテナオーケストレーション (Kubernates / ECS / Swarm など) を用いてコンテナ群を実行する
アプリケーションプロセスの管理とスケール
スケーラブルなアプリケーションプロセスが満たすべき要件。
VI. プロセス
- アプリケーションの実行は 1 つ以上のプロセスからなる
- プロセスは ステートレス である
- プロセスは シェアードナッシング である
永続化する必要のある全てのデータは、ステートフルなバックエンドサービス (DB など) に格納する。
VIII. 並行性
プロセスはアプリケーション実行の最小単位である。
- アプリケーションのエントリーポイントは、プロセスの単なる起動である
- プロセスをデーモン化する機能、PID を吐く機能などをアプリケーション自体に持たせるべきではない
- 統合的に、OS の標準機能やプロセスマネージャに任せる (Upstart, launchd, foreman)
- プロセス単位でスケールアウトする
- シェアードナッシングなプロセスは容易に並行動作可能
IX. 廃棄容易性
コードのデプロイやプロセスの再配置 (スケーリング) のためにプロセスはいつでも再起動される可能性があり、それに備えなければならない。
- プロセスは SIGTERM シグナルに対して、グレースフルにシャットダウンする
- Web プロセス: ポートのリッスンを停止、処理中のリクエストの完了を待ち、シャットダウン
- ワーカープロセス: ジョブをキューに戻す
- 突然の死 (SIGTERM 無し) に対しても堅牢であるべき
- プロセスの起動時間を最小化する
🐳 Docker への適用
プロセス = コンテナ (or コンテナ内で起動するプロセス) と読み替える。
- コンテナは原則ステートレス・シェアードナッシングとする
- 永続化領域 (VOLUME) は慎重に扱う必要がある
- 例外的にステートフルなコンテナ (データベースなど) を扱う場合は、その他のステートレスなコンテナとは明確に分離する
- コンテナ内で起動するプロセスはデーモン化しない
- コンテナプロセスの管理はコンテナの外側でコンテナオーケストレーションシステムが担う
- コンテナは SIGTERM を正しくハンドリングする
- コンテナの起動時間を最小化する
運用
本番運用のための統一的なインタフェースの指針。
XI. ログ
XII. 管理プロセス
一回きりの管理・メンテナンスタスクについて。
- REPL シェル (rails console など) や単発タスク (DB マイグレート、Rake タスク など) を、本番環境で実行できるようにしておく
- このためのコードは、アプリケーションコードと同じコードベースで管理し、一緒にデプロイする
- 同期の問題を避けるため
🐳 Docker への適用
- コンテナ内のプロセスはログストリームを標準出力に書き出す
- Docker の Logging Driver は、標準出力をハンドリングすることを想定している
- Docker イメージはアプリケーションプロセスの実行と共に、REPL シェルやタスクの実行を想定するべき
bundle exec rake XXXやbundle exec rails console- 例えば postgres イメージは、以下の機能を同時に提供している (Best practices for writing Dockerfiles)
docker run postgres: postgres の起動docker run --rm -it postgres bash: シェルの起動
参考
Haskell で始める AtCoder Beginner Contest
Competitive Programming Advent Calendar 2015 五日目の記事です。
Beginner Contest レベルなら、呪文みたいな大量のコード (レギュラーコンテストに出てる人たちのコードはすごい) を書かないでも、意外とシンプルに書けることが多くて、パズル感覚で楽しめます。
Haskell で ABC をやる上で僕が感じた楽しいところ、楽しくないところをご紹介します。
楽しいところ
1. 関数が豊富
import Control.Monad main = do n <- readLn putStr . unlines . replicateM n $ "abc"
重複ありの組み合わせは replicateM 関数で作れるので、このようにびっくりするほど短く解けます。
他にもリストの基本操作 (sort, map, ...) から、置換や複数行文字列との相互変換まで、一通りの関数がそろっています。
http://hackage.haskell.org/package/base-4.8.1.0/docs/Data-List.html
replicateM は Control.Monad モジュールで定義された関数です。
http://hackage.haskell.org/package/base-4.8.1.0/docs/Control-Monad.html#v:replicateM
2. 関数定義が軽い、再帰が軽い
import Control.Applicative import Control.Monad solve x y as bs c = case as of (a:as) -> solve y x (dropWhile (<x+a) bs) as (c+1) otherwise -> c `div` 2 main = do -- 入力 [n, [x, y], as, bs] <- replicateM 4 $ map read . words <$> getLine print $ solve x y as bs 0
基底部を除くと実質
solve x y (a:as) bs c = solve y x (dropWhile (<x+a) bs) as (c+1)
これだけです。短い!
多少複雑な問題でも
リスト構造が汎用的なので工夫でなんとかなることも多い。(ここがパズル的でおもしろい)
import Control.Applicative import Data.List solve bs n = val $ map (solve bs) $ elemIndices n bs where val [] = 1 val bs = maximum bs + minimum bs + 1 main = do _ <- getLine bs <- map (pred . read) . lines <$> getContents print $ solve (-1:bs) 0
楽しくないところ
Haskell で ABC をやる上で僕が感じた、楽しいくないところ
IO が遅い
標準的な入力関数で String 型で読み込むと、重くて TLE しばしば。
仕方なく、おまじないを使います。
import qualified Data.ByteString.Char8 as BC import Data.Maybe (fromJust) readInts = map (fst . fromJust . BC.readInt) . BC.words <$> BC.getLine
参考: Wc - HaskellWiki
List の弱みが辛い
- ランダムアクセスが O(N)
- 値がイミュータブル
一応 Map/IntMap, Array, Vector など使えば解決できるっぽいですが、僕はまだ自在に泳げるほど慣れていません。
いずれにしても破壊的代入は実装が嵩んで辛くなりそう。。慣れるのかな。
これらを使わないで解ける問題はやっぱり限られます。
List だけで自明に解けた問題
ABC 026 - 030 で、List だけを使う解法を見つけられた問題と、見つけられなかった問題。
| コンテスト | A | B | C | D |
|---|---|---|---|---|
| ABC023 | o | o | x | o |
| ABC024 | o | o | o | o |
| ABC025 | o | o | o | x |
| ABC026 | o | o | o | o |
| ABC027 | o | o | o | o |
| ABC028 | o | o | o | o |
| ABC029 | o | o | o | o |
| ABC030 | o | o | o | x |
たま〜に、List だけでは素直に解けない気がする問題があります。解けない問題のほとんどは Map/IntMap でなんとかなって、ごく一部が Array/Vector まで要求される感じです。
Map/IntMap はそこまで怖くないので、積極的に使ったら良いかもしれないです。
余談
余談ですが最近、会社の人達と集まって AtCoder Beginner Contest をやっています。

初心者の方もいるので、経験者は得意言語を使わない縛りみたいな、僕は Haskell 縛りをしていたわけです。
競技プログラミングの布教活動のつもりだったけど意外に楽しんでもらえていて、だんだんみんな強くなってくるし、良いですよ。
ICFPC 2015 参加記
ICFPC2015 にソロで出た。刺激的な三日間でした。
一日目
朝
問題を読む。
Ruby でコマンドラインで可視化しながら Qualification Problems の json を読む。
12:00
Problem 1 を単純に左下詰めで提出して、とりあえず正のスコアを取った。
15:00
- Source から出てきた Unit に対して, Lock 可能位置 (lockable) を全列挙する
- 評価関数を使って最もスコアの良い lockable を採用する
source の先読みはやらない。 (余裕があれば考える)
17:00
気分転換に外出してゴルフ。
23:00
lockable の列挙ができた。
評価関数 (仮) を作って、それに基いて動く AI ができた。
と思いきや、盤面の実装がハニカムになっていない (矩形になってる) ことに気付いて、ふて寝。
これ、ハニカムになってない…
— 高知・夏・17歳 (@na_o_ys) 2015, 8月 9二日目
12:00
ハニカム化ができた。
テトリスちゃんかわいい(全然消してくれない) pic.twitter.com/Kkq9tjAbPK
— 高知・夏・17歳 (@na_o_ys) 2015, 8月 9http://www.redblobgames.com/grids/hexagons/ を参考に、
- Board は直交座標系で管理
- Unit の移動と回転の際に, Axial 座標系を介する
14:00
入出力の部分に取り掛かる。
[problem.json] - IO(Ruby) - [answer.json]
|
AI(C++)
15:00
提出しては 0 点、デバッグ、の繰り返し。
バグバグバグ、身が削れる
— 高知・夏・17歳 (@na_o_ys) 2015, 8月 917:00
いくつかのバグを倒す。
半分くらいの問題で正の得点が取れた٩(๑❛ᴗ❛๑)۶
休憩。
21:00
バグが無くならない!
三日目
朝
12:00
15:00
バグが取れたか…?
— 高知・夏・17歳 (@na_o_ys) 2015, 8月 10バグ取れたーーーーー(感涙)
— 高知・夏・17歳 (@na_o_ys) 2015, 8月 10やっと評価関数が作れるぞ。
17:00
でこぼこを少なくするためには、表面積を小さくすれば良い。
各空きマスの周囲の埋マス数に、行番号で傾斜をかけた値を評価値とした。
人並みのスコアになった。
21:00
Qualification 114 位でした。

振り返りと気付き
大半の時間がデバッグだったけど、最終的に書いたものが全部動いたので、良かった。
アルゴリズムについて
アルゴリズムに関しては、まだ改善の入り口にも達していない感じがする。
数日かけて実装するコンテストに出たのが初めてで、実装してる間も力不足を感じた。
ビームサーチとか、探索系アルゴリズムを組む練習をしていこう。
デバッグが辛かった
コーディングしてる間は楽しいんだけど、デバッグが何時間も続くと気が狂ってくる。
セブンイレブンで甘い物仕入れて食べてた。糖分を取ると集中力がウソみたいに上がる。
チームで出たい (重要)
チームだったらあれもこれも出来るのになーと思いながら開発していた。
AI に関しては方針の相談とか、デバッグのお手伝いとか。息抜きとか。
あと開発の補助的な部分が多分とても大きくて、
- AI のバージョン管理、スコア管理ツール
- ビジュアライザ・シミュレータ
など、あるのと無いのでは効率が全然違うが、ソロだと作ってる暇が無い。
クラウド環境が欲しかった
AI によっては問題を実行する度に 5 分くらい待ち時間が出て、めんどうだった。
AWS でスーパーマシンを用意しておくと捗ると思った。
楽しかった
今年に入ってから、開発合宿に何度か行ったり、数日根詰めて開発する機会が多い。
短期集中で目に見えるものを作ると達成感があるし、なんとなく、集中力の幅が広がる気がする。
長期間で大きなことをするのが苦手な性格っぽいので、こういう機会を大事にしていきましょう。と思った。
お疲れ様でした!
どうぶつしょうぎの盤面認識アプリを作る (4) 駒の認識
(1) 準備編
(2) 勉強編
(3) 盤面の正規化
(4) 駒の認識
正規化された入力画像から、各駒の位置を取得します。
- 駒 (先手ゾウ) の位置を特定

概略
- 駒の画像を用意する
- テンプレートマッチングで駒の位置を特定する
- 駒が傾いている場合を考慮して、複数の角度でマッチングする
駒画像





テンプレートマッチング
真っ直ぐに置かれている駒については、正しく認識されますが、盤に対して傾いている駒が認識されません。
そこで、-70 度 〜 +70 度の 2 度刻み回転した駒画像生成し、マッチングさせます。
入力画像の歪みが小さければ、これで高い精度でマッチングできるようです。
棋譜データへの変換
取得したデータを別プログラムに流し込むため、文字列データに変換します。
今回の入力画像からは次の配列が得られます。
[['k' '' 'z'] ['l' 'h' ''] ['' 'H' ''] ['Z' 'L' 'K']]
どうぶつしょうぎの盤面認識アプリを作る (3) 盤面の正規化
(1) 準備編
(2) 勉強編
(3) 盤面の正規化
(4) 駒の認識
カメラで撮影した画像から、盤面のみを取り出して固定位置に正規化します。
- 入力画像

- 正規化後の入力画像

手法
- 盤面のみの画像を用意する
- 入力画像と盤面画像で特徴量抽出・マッチングする
- マッチングで得られた射影変換を盤面画像全体に適用する
盤面画像
きれいな長方形になっている盤面画像を用意します。

特徴量抽出
盤面画像と入力画像の特徴を抽出します。
今回は AKAZE 特徴量っていうのを使ってみました。
- 盤面画像

- 入力画像

盤面画像については、マス目の内側を特徴量抽出から除外しています。
マッチング
今回は速度面はどうでもいいので、Brute-Force Matcher を使います。

マッチングから射影変換を取り出して、入力画像に適用することで、正規化画像が得られます。
問題点
盤面の特徴点は「どうぶつしょうぎ」のロゴの部分に集中しています。
ロゴ部分の角度のみを反映した射影変換となるため、カメラレンズの歪みによって盤面がきれいな台形になっていない入力画像については、正規化後の画像が大きくはみ出してしまいます。

使用する特徴量やパラメータの調整によって、ロゴ部分以外からもうまく特徴点を抽出できれば、ある程度改善できそうです。
どうぶつしょうぎの盤面認識アプリを作る (2) 勉強編
(1) 準備編
(2) 勉強編
(3) 盤面の正規化
(4) 駒の認識
画像を盤面情報(駒の配置、持ち駒)に変換するためには、次のような処理が必要となる。
- 画像内でのボードの座標取得
- 画像内での各駒の座標取得
- 上記内容をもとに盤面情報を計算・生成
1, 2 はあらかじめボード・駒の画像を用意しておき、それを元に入力画像内での位置を検出する、マッチングという手法が使える。
Template Matching と Feature Detection and Description (特徴抽出と特徴記述) の内容を勉強する。
Template Matching
テンプレート画像と入力画像を与えて、入力画像の中でテンプレート画像が出現する箇所の座標を抽出する。
Feature Detection and Description
大事そうな章だけ抜粋
Understanding Features
- 画像の「特徴」とは何か
- 面より辺、辺より角の方が、特定しやすい→特徴的
- 特徴とは、変化量が大きい領域
- 特徴を探すことを特徴抽出と呼ぶ
Harris Corner Detection
- 明度の変化量から、角を抽出するアルゴリズム
Introduction to SIFT (Scale-Invariant Feature Transform)
- 角は、拡大すると角じゃなくなるかもしれない(実は丸いかもしれない)
- つまり Harris Corner Detection はスケール不変ではない
- スケール不変な特徴が欲しい
- SIFT はスケール不変な特徴を与える
- 4 つのステップからなる
1. Scale-space Extrema Detection
特徴点候補を見つける。
窓関数のサイズ (scale) と位置 (space) の 2 パラメータについて、近傍の変化量が極大となるような値を列挙する。
- scale はガウシアンの分散 (幅)
- scale 毎に, space 毎のラプラシアン (実際は Difference of Gaussian, DoG) を取る
- ラプラシアンは明暗の差が大きい部分で値が 0 から離れる
- space と scale について極値を探す
2. Keypoint Localization
特徴点候補のうち無意味なものを除外する。
3. Orientation Assignment
回転に対して不変性を得るために, 特徴点に方向を与える。
- 36 方向の勾配強度を求める
- 最大値の 80 % 以上のものを抽出して、別個の特徴点として保持する
- マッチングの安定性に寄与する
4. Keypoint Descriptor
特徴点周辺の情報を集めて、特徴点記述子を作る。
- 特徴点の周りの 16 * 16 の領域から、8 方向の勾配強度を取る
- 4 * 4 のサブブロックに分けて、8 方向の勾配強度の和を取る
- 合計 4 * 4 * 8 = 128 の値を特徴点記述子とする
資料だと説明が簡素で意味不明だが、論文 の Figure 7 の説明が分かりやすい。
5. Keypoint Matching
2 つの画像の特徴点同士をマッチングする。
BRIEF (Binary Robust Independent Elementary Features)
SIFT の特徴点記述子はマッチングにおいて冗長である。
マッチングにおいては、速度面の理由から特徴点記述子が binary string に変換される。
BRIEF は同様に binary string に高速で変換可能な、圧縮された特徴点記述子である。
OpenCV では特徴点抽出器 (FeatureDetector)、特徴点記述子生成器 (DescriptorExtractor) がそれぞれインタフェースとして定義されている。
# Initiate STAR detector
star = cv2.FeatureDetector_create("STAR")
# Initiate BRIEF extractor
brief = cv2.DescriptorExtractor_create("BRIEF")
# find the keypoints with STAR
kp = star.detect(img,None)
# compute the descriptors with BRIEF
kp, des = brief.compute(img, kp)
Feature Matching
画像 A の特徴点を、画像 B の特徴点にマッチングする。
Brute-Force Matcher
crossCheck を on にすると、画像 A の特徴 i にとって画像 B の特徴 j が最もマッチしているだけでなく、逆も成り立っている場合のみマッチしたとみなす。
FLANN Based Matcher
速い。
Feature Matching + Homography to find Objects
- findHomography: マッチの集合から、ホモグラフィ行列とインライアー(正しいマッチ)/アウトライアーのマスクを求める
- RANSAC: インライアーとアウトライアーのしきい値を指定する
- perspectiveTransform: 点をホモグラフィ行列をもとに投影変換する
まとめ
付け焼き刃なので間違いが多いと思います
マッチングには、テンプレートマッチングと特徴マッチングがある。
テンプレートマッチングはシンプルだが、テンプレートのサイズと角度が対象画像内のオブジェクトのそれと一致している必要がある。
特徴マッチングでは、スケール不変・回転不変な特徴を用いることで、拡大率が異なったり傾いた画像に対してもマッチングすることができる。ただし、対象画像内に対象オブジェクトが複数ある場合はそのままではマッチングできない。
今回の場合、盤面座標を求めるのには特徴マッチングが使える。 求めた盤面座標を元に画像を正規化 (角度・拡大率をノーマライズ) することで、テンプレートマッチングを使って駒座標を求めることができる。